
In the rapidly evolving world of artificial intelligence, large language models (LLMs) are making headlines for their remarkable ability to understand and generate human-like text. These advanced models, built on sophisticated transformer architectures, have demonstrated extraordinary skills in tasks such as answering questions, drafting emails, and even composing essays. Their success is largely attributed to their extensive training on vast amounts of text data and their impressive number of parameters, which enable them to perform complex language processing tasks with high accuracy.
However, despite their impressive capabilities, LLMs face significant challenges when it comes to real-time applications. One of the key issues is their speed. The very features that make these models powerful—such as their auto-regressive decoding methods and their large size—can also lead to slower response times. This delay can be a major drawback in scenarios where quick and efficient interaction is crucial, like customer service or live chat support.
Furthermore, the “chain-of-thought” (CoT) technique, which helps LLMs tackle complex queries by breaking down the problem into manageable steps, can sometimes result in longer, more detailed responses. While this approach enhances the model’s accuracy and reliability, it also exacerbates the problem of latency, further slowing down the response process.
To address these challenges, researchers are exploring various strategies to speed up LLMs without sacrificing their effectiveness. Innovations such as model pruning, quantization, and early-exit techniques are being developed to streamline these models, making them faster and more efficient. Additionally, new decoding methods are being introduced to improve response times, ensuring that businesses can leverage the full potential of LLMs while maintaining smooth and prompt interactions.
In this blog, we will delve into these advancements and explore how they can benefit businesses by enhancing the performance and efficiency of AI-driven solutions. Whether you’re a business executive looking to integrate AI into your operations or simply curious about the latest in AI technology, understanding these developments will provide valuable insights into how LLMs are evolving to meet the demands of modern applications.
The Solution: Introducing LiveMind for Enhanced AI Responsiveness
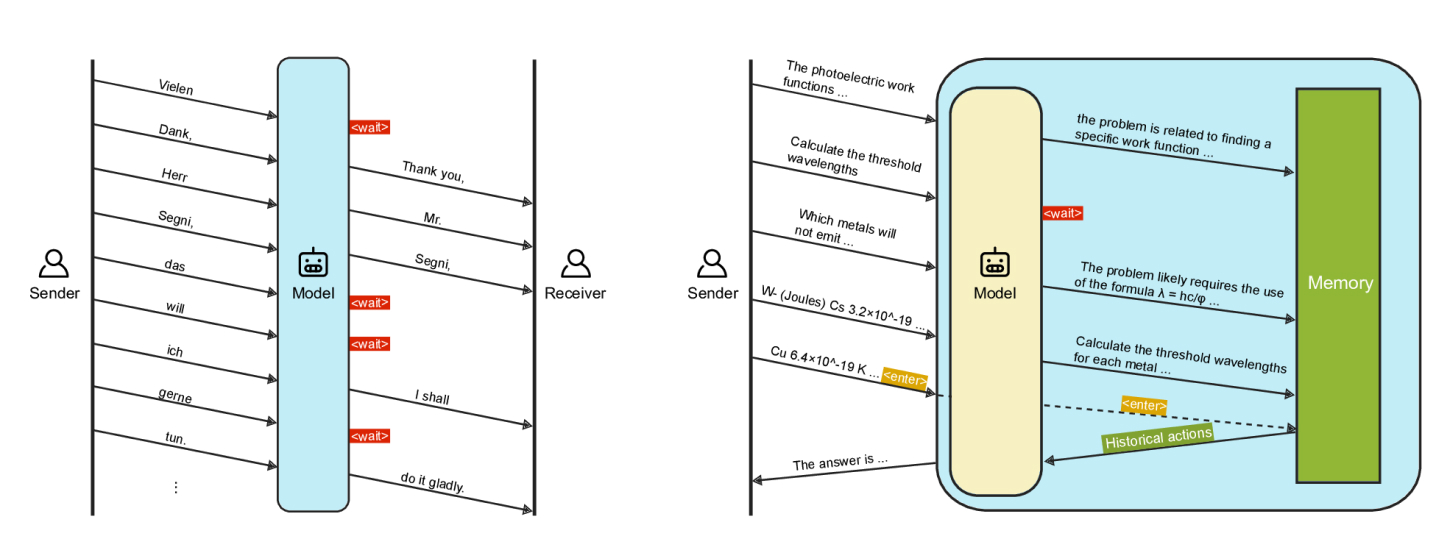
While large language models (LLMs) have revolutionized the way we interact with AI, the challenge of latency remains a significant hurdle. Traditional LLM interfaces often require the entire user prompt before they can begin generating responses, which means that users experience delays as the model waits to receive and process the complete input. This approach, while effective in ensuring accuracy, can be slow and cumbersome, particularly in dynamic or real-time interactions.
To tackle this issue, we propose an innovative solution inspired by the way humans naturally converse. Just as people can process and respond to ongoing conversations while listening, LLMs can also be adapted to handle input incrementally. Our solution, called LiveMind, introduces a novel approach that allows LLMs to initiate inference while the user is still providing input. This concurrent processing can significantly reduce the delay between receiving a prompt and delivering a response.
How LiveMind Works
LiveMind transforms the way LLMs handle user input by enabling them to process incomplete prompts during the input phase. Here’s a closer look at how it works:
- Concurrent Inference: Instead of waiting for the complete prompt, LiveMind allows the LLM to start processing as soon as the user begins typing or speaking. This means the model can begin analyzing and generating preliminary inferences based on the partial input it receives.
- Streaming Input: As the user continues to provide additional information, LiveMind dynamically updates its understanding of the prompt. This streaming approach allows the model to refine its responses in real-time, leveraging the time during which the input is still being entered.
- Efficient Final Processing: Once the complete prompt is received, LiveMind utilizes the preliminary inferences it has generated to quickly finalize the response. This step is significantly faster compared to conventional methods, where the model must process the entire prompt from scratch.
- Optimized Latency: By splitting the inference process into two stages—preliminary processing during input and final refinement upon receiving the complete prompt—LiveMind effectively reduces the latency experienced by users. The majority of the processing is done while the user is still interacting, which minimizes the waiting time for the final response.
Understanding Simultaneous Inference in Large Language Models (LLMs)
To further optimize performance, LiveMind incorporates a hybrid approach using both a large language model (LLM) and a small language model (SLM). During the preliminary inference stage, the LLM handles the complex processing, while the SLM assists during the final output stage. This combination not only speeds up the overall response time but also maintains a high level of accuracy, leveraging the strengths of both models.
Simultaneous inference refers to the capability of a model to process and generate outputs in real-time as inputs are received, rather than waiting for the complete input before starting the generation process. This approach is particularly relevant in applications where immediate feedback is crucial, such as interactive dialogue systems and real-time translation.
Key Insights into Simultaneous Inference
Simultaneous inference has been primarily explored in sequence-to-sequence (seq-to-seq) tasks, particularly in machine translation. In these tasks, the model translates input text into output text, generating translations as new words are received. Techniques such as prompting the model with new requests or fine-tuning it to use special tokens (like a “wait” token) facilitate simultaneous outputs.
The framework was tested with Llama-3-8B and Llama-3-70B models on various domain-specific questions. Results indicated a significant reduction in latency compared to conventional methods, with a 59.2% average reduction for the Llama-3-70B model and a 93% reduction when combining Llama-3-70B with Llama-3-8B, alongside a 5.5% accuracy increase over the Llama-3-8B baseline. These findings suggest that LiveMind effectively reduces latency while maintaining or enhancing accuracy, indicating its potential for future LLM applications.
Overall, the LiveMind framework represents a substantial advancement in enabling real-time, interactive AI systems by utilizing simultaneous inference techniques and model collaboration.







.png)


