
GenAI pilots are proliferating across industries, yet advancing these initiatives into full-scale production remains a major challenge. A recent MIT study revealed that 95% of generative AI projects fail to move beyond the pilot stage. During the early stages, organizations often concentrate narrowly on model accuracy and performance. While these measures are important, they are far from sufficient when it comes to preparing a Generative AI pilot to production. True success requires a broader focus on operationalization, scalability, and enterprise integration.
Bridging the gap between proof-of-concept and production requires deliberate planning across both technical and strategic dimensions. Organizations must assess their readiness not just in terms of the model itself but in how the entire solution operates within the enterprise context. This involves building the right foundations for monitoring and governance, ensuring reliability and cost efficiency, and establishing frameworks for continuous improvement.
Why the majority of projects are failing?
The truth is, building an agent is the easy part — it’s basically software engineering with some prompt craft and API wiring. The real challenge starts the moment you expose it to unpredictable real-world inputs and traffic patterns. Suddenly, you’re not just debugging code, you’re debugging reasoning chains, API misuse, and hallucination-driven chaos. That’s why “AgentOps” matters: it’s the discipline of managing nondeterministic systems with deterministic business requirements. Without robust infra for observability, guardrails, and cost controls, even the most elegant agent prototype collapses under production pressure. As Eduardo Ordax )Generative AI Lead at AWS) points out, deploying agents isn’t just DevOps or MLOps — it’s a whole new frontier of infrastructure.
The reasons why the majority of projects fail aren’t always obvious. But when you take a step back, a clear pattern begins to emerge. Pilots often fail not because the models are weak, but because the systems surrounding them never mature. They remain flashy demos instead of evolving into dependable services. The following are the major reasons;
1. Learning Gap, Not Model Gap
The industry often frames the challenge as a “model problem”—waiting for better models to deliver ROI. But the reality is a learning gap. Most enterprise pilots fail because they don’t adapt to real workflows or learn from outcomes. As a result, they don’t capture useful outcomes or generate insights that inform improvement.
Without adapting to real use and learning from results, these pilots rarely scale or drive lasting impact. This creates a “demo purgatory”: tools look impressive in a sandbox, but never evolve into production systems that learn and adapt. MIT’s analysis highlights that only ~5% of pilots translate into measurable revenue impact, while the vast majority stagnate in pilot mode.
Bud is designed to make sure AI pilots don’t just look good in a sandbox but actually deliver results in production. It does this by embedding learning, adaptation, and workflow integration into every layer of its Foundry:
- Bud AI Gateway goes beyond serving responses by actively learning from user feedback and applying test-time scaling. This means the system improves continuously, rather than staying fixed at demo accuracy.
- Bud’s Agent & Tool Runtime transforms models from passive responders into active workflow agents. Built on a Dapr-based, internet-scale runtime, it supports production-ready protocols like A2A (Agent-to-Agent) and ACP (Agent Control Protocol), enabling agents to coordinate, call tools, and adapt dynamically. With MCP orchestration and access to over 400+ modular components, enterprises can plug in tools, data sources, and APIs without heavy engineering. The runtime also generates artifacts—customizable, shareable UI elements—so end-users can turn these agents into real applications that evolve with use. This ensures agents don’t just answer questions but learn from outcomes, refine workflows, and drive measurable business impact.
- Bud Evals & Guardrails – Built-in evaluation and over 160 guardrails ensure agents and models are measured against real-world benchmarks, compliance requirements, and user-specific outcomes. Instead of static demos, enterprises get evolving, trustworthy systems.
Together, these features transform pilots from one-off experiments into living, adaptive systems that learn from real use, scale with demand, and deliver measurable ROI.
2. Weak Integration with Enterprise Data & Processes
AI tools are often “bolted on” rather than embedded. Ad-hoc retrieval-augmented generation (RAG) pipelines or brittle tool-use wrappers don’t mesh with enterprise systems of record or service-level agreements (SLAs). Instead of becoming part of the process fabric (ERP, CRM, HRIS, ticketing), they remain add-ons. This limits trust, creates duplicative workflows, and prevents AI from driving core business outcomes.
Bud addresses this with robust tool orchestration and a unified data and knowledge layer designed for real enterprise integration.
- Knowledge & Data Layer
Connects to 200+ enterprise data sources, with built-in semantic search, S3-compatible object storage, and secure vaulting. Supports integration of external tools and managed computation providers (MCPs), ensuring both flexibility and governance. - Unified Multi-Modal Runtime
A single, integrated runtime that brings together LLMs, embeddings, OCR, speech-to-text (STT), text-to-speech (TTS), and tool execution. This means RAG and tool-use operate in one coherent, reliable stack—instead of being stitched together with fragile services. It ensures consistency, observability, and performance at scale.
3. Operational Complexity & Infrastructure Sprawl
Production AI isn’t just “call a model.” It involves multi-model routing, multi-modal stacks, caching, scaling layers, guardrails, and observability. Each added dimension multiplies complexity. Without mature MLOps and platform engineering, this combinatorial sprawl overwhelms teams. The result: brittle pilots that can’t be productionized reliably or safely.
Bud was designed from the ground up to eliminate this complexity by providing an end-to-end, production-ready AI platform with zero-config deployment, and self-optimizing performance — all within a single, unified runtime. Bud’s runtime abstracts away the operational overhead of managing diverse AI workloads. The runtime can automatically distribute workloads across heterogeneous compute environments — including CPUs, GPUs, and HPUs — optimizing performance while reducing cost.
- Built-in self-healing mechanisms detect and recover from failures automatically, reducing downtime and the need for manual intervention.
- Performance optimization is effortless. Bud uses auto-quantization and kernel tuning to ensure each model runs at peak efficiency — no manual tweaking required.
- Bud Scaler, Bud’s SLO-aware autoscaler, dynamically allocates resources based on your business goals. It routes requests using a combination of geographic proximity, model accuracy, and KV-cache awareness — improving both latency and consistency. Distributed KV stores reduce duplication and enhance context reuse.
- Before going live, simulate first. BudSim lets you test different infrastructure and model configurations using realistic traffic and workload data. It helps you understand cost–performance trade-offs upfront and recommends optimal deployment setups aligned with your SLOs. Avoid overprovisioning and eliminate costly trial-and-error in production.
Bud doesn’t just scale — it scales smart. Infrastructure usage aligns with your operational goals and budget from day one. You get high performance and resilience out of the box — no need for a dedicated infra team to tune every detail. And with BudSim, you gain confidence in performance and cost predictability before a single production request is made.
4. Talent & Time Bottlenecks
Few enterprise teams have engineers who’ve shipped distributed, multi-node, multi-modal AI systems. Even fewer can balance UX, infra, data, and security simultaneously. Skills shortages cause pilots to drag on for months, blowing past budget cycles. The scarcity of talent amplifies risk: organizations hesitate to scale something they can’t confidently operate.
Bud makes everyone an AI builder — with infrastructure that configures itself.
- Bud Studio is a user-friendly platform (PaaS) that allows anyone — even non-technical users — to deploy GenAI applications, build intelligent agents, and scale effortlessly.
- Bud Agent acts as a built-in technical assistant, automating the complex parts of GenAI infrastructure setup and management. It’s GenAI that manages GenAI — so your team doesn’t have to.
5. ROI & FinOps Missing
Many pilots are funded as “cool demos” without clear service-level objectives (SLOs), unit economics, or cost controls. Enterprises fail to track token usage, latency, throughput, or dollar ROI. Without FinOps discipline—measuring cost-per-output, SLA adherence, and incremental value—budgets drain while the business case remains unproven. Leadership inevitably stalls further investment, cementing pilots as experiments, not platforms.
- Bud solves this with AI FinOps: built-in budgeting tools, rate limiting, per-cluster model billing, cost-aware auto-optimization, and a comprehensive observability cockpit.
6. Governance, Security & Compliance Gaps
Enterprises operate in regulated environments. Yet governance, privacy, PII redaction, and abuse prevention are often bolted on late in the cycle. This creates last-minute compliance red flags that delay or block launches. Regulators, CISOs, and legal teams push back because guardrails weren’t designed-in. The absence of early governance planning means otherwise promising pilots die at the gate to production.
Bud solves this problem by embedding security and compliance directly into the GenAI lifecycle. Its built-in guardrails and advanced security analysis features ensure that governance isn’t an afterthought — it’s a foundation.
- Bud SENTRY is a security module within Bud Runtime designed to protect AI model workflows from supply chain attacks. It enforces a Zero Trust ingestion lifecycle by scanning, isolating, and monitoring every model — both before and during deployment. All models are processed in a secure, sandboxed environment, rigorously scanned for malware and anomalies, and continuously monitored at runtime for suspicious behavior. This entire process is seamlessly integrated into Bud Runtime, offering robust protection through a simple one-click interface — no deep security expertise required.
- Bud Sentinel is a comprehensive security and compliance suite for GenAI systems — covering models, prompts, agents, infrastructure, and clusters. It leverages a Zero Trust framework to secure model download, deployment, and inference. Sentinel provides ultra-low-latency guardrails (<10ms) and multi-layered content scanning using regex, fuzzy matching, classifiers, and LLM-based techniques. With over 300 prebuilt probes — and support for fully customizable probes via Bud’s Symbolic AI — Sentinel offers flexible, granular threat detection. Future support for confidential computing across Intel, Nvidia, and ARM platforms will further enhance runtime protection.
Together, Bud SENTRY and Bud Sentinel enable organizations to move fast without compromising on trust, compliance, or security — ensuring your GenAI infrastructure is protected by design, not by patchwork.
7. Build-vs-Buy Trap
Enterprises frequently default to internal builds, assuming control equals performance. In practice, these homegrown systems struggle with scalability, latency, and reliability. Purchased or managed platforms often outperform because they bring hardened tooling, pre-integration, and ongoing upgrades. Internal builds rarely cross the integration/operations threshold to production. Organizations end up with partial prototypes that consume budget but never deliver business-ready services.
How Bud Makes Your Generative AI Pilot to Production Journey Successful
Bud AI Foundry’s full-stack architecture covers every layer — from infrastructure to orchestration, from model lifecycle management to agent deployment, and from governance to end-user experience. With integrated guardrails, zero-trust security, observability, and cost-optimization frameworks, Bud ensures your AI systems don’t just demo well — they thrive in production. The table below shows the different layers of Bud AI Foundry architecture and the key features provided at each stage to ensure a seamless, secure, and scalable journey from pilots to enterprise-grade production.
| Layers | Features |
| Governance Layer | -Full Stack AI App & Service Governance: Operations, security, compliance -Model Routing: Based on SLOs, accuracy, cost, language, compliance -AI FinOps: Budgeting, rate limiting, billing models, cost-optimized scaling -Monitoring & Observability Cockpit -Bud SENTRY Framework: Zero-trust security for model weights, tools, data, and I/O -Bud Evals: Evaluation suite for models and agents (140+ benchmarks supported) -Bud Guardrails: 160+ guardrails for agent, model, and multi-modal system safety -Bud Simulator: Simulate and identify optimal hardware and cost configurations |
| Consumption Layer | -Bud Studio: Platform to create, consume, and share agents and prompts -SDKs: For multi-modal agents, models, guardrails, etc. -End-User Dashboard: OpenAI-like user experience -AI Platform-as-a-Service (AI PaaS) -End-User Authentication & Access Control |
| Agentic Layer | -Integrated Agent, Prompt, and Chatflow Builder -Internet-Scale Agent Runtime -AI Gateway with Learning Capabilities: Multi-Modal support, MCPs, guardrails, service tiers -MCP Orchestration & Virtual Servers -Universal Agent: Capable of building other agents -Prompt Optimization & Agent Tooling |
| Model Layer | -Model Lifecycle Management: Develop, train, deploy, and serve models across various use cases -Truly Multi-Modal Foundation Models: Text, Embeddings, Images, Audio, Actions -Hardware & Engine Agnostic Model Runtime -Zero-Config Model Deployment -Performance Optimization: Automated quantization, kernel tuning -Model Inferencing Services: API endpoints for various inference needs |
| Knowledge & Data Layer | -AI-Ready, Secure, and Localized Data Infrastructure -200+ Data Source Integrations -Synthetic Data Generation and Batched Workloads -Semantic & Vector Services (Vector DB support) -S3 Compatible Object Storage -Comprehensive Data & Knowledge Management: Vaults, encryption, cataloging, data quality tools -Supports external tool deployment (on top of RHOS AI or other platforms) |
| Orchestration Layer | -Multi-Tenant Elastic Orchestration for AI workloads -Bud Scaler: Zero-config scaling of models, tools, and components -Multi-Tenancy & Multi-LoRA Serving: Supports model card isolation and serving multiple adapters from a single card -Containerization Support: Kubernetes, container services, registries -Serverless Functions, Virtual Tools (MCPs), and UI Fragments -Intelligent Scaling & Scheduling across Bare Metal, VMs, Virtual Clusters, Model-as-a-Service, and AI PaaS |
| Infrastructure Layer | -Scalable, Sovereign AI Compute, Storage, and Network Capabilities -Bud Accelerated Compute Stack (Optimized Compute, Storage, Network) -General Compute Stack (Standard CPU-based Compute, Storage, Network) -Edge & Data Center Integration (Support for deployments at customer locations and edge sites) -Hyperscaler Integration (Seamless integration with public cloud providers) -Heterogeneous Infrastructure with support for parallelism and hybrid deployments |
Scale Easy With Bud AI Foundry
Production GenAI workloads often involve large models and unpredictable user demand. Easy scalability ensures the system can handle increasing load or larger models without performance degradation. Scalable infrastructure allows generative models to serve high-volume applications (e.g. customer support chatbots or content generation) by handling large data volumes and user interactions efficiently. This means organizations can meet growing usage without compromising response time or quality. Techniques like containerization and orchestration (e.g. using Kubernetes) enable horizontal scaling across multiple compute nodes. In cloud environments, autoscaling can dynamically add resources during peak demand and scale down to control costs. Easy scalability is critical to maintain a good user experience as the popularity of GenAI services grows, and to adapt if the underlying model needs more computation (for example, deploying a larger LLM with more parameters).
Guardrails for Safe and Ethical AI
Generative AI models can sometimes produce incorrect or inappropriate outputs, so deploying them responsibly requires guardrails. AI guardrails are safeguards that keep the model’s behavior aligned with organizational policies, ethical standards, and legal requirements. They can automatically filter out or modify outputs that are toxic, biased, or factually incorrect, preventing unsafe content (e.g. hate speech, misinformation or privacy violations) from reaching end-users. Guardrails are crucial for the responsible use of GenAI: they help identify and remove hallucinations or policy violations in model outputs, and can even monitor incoming user prompts to catch risky requests.
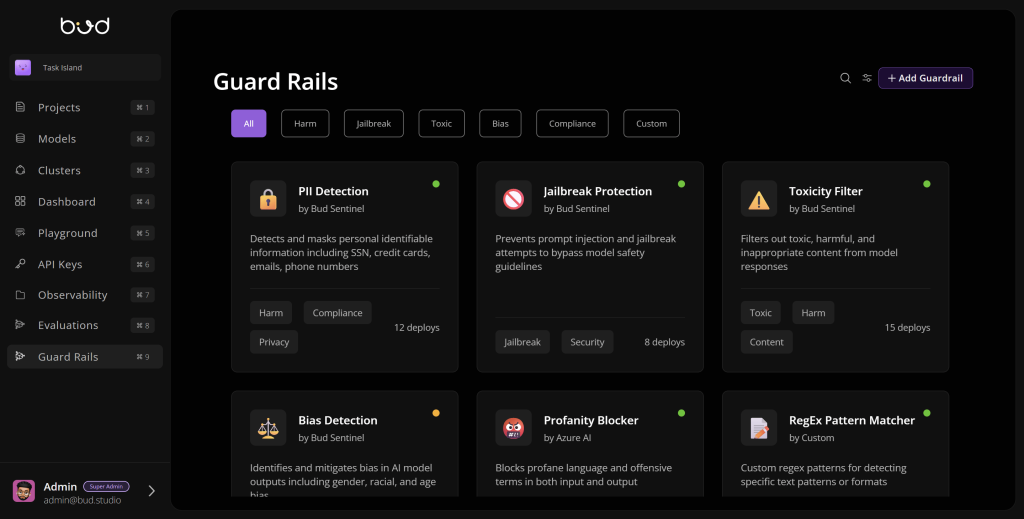
Bud’s AI Foundry is designed with a built-in guardrail system that ensures every generative AI solution is safe, compliant, and enterprise-ready. By embedding controls for security, privacy, ethical use, and regulatory compliance directly into the development pipeline, the Foundry enables organizations to innovate with confidence—scaling GenAI applications without compromising on trust or governance.
Implementing guardrails brings several business benefits. It mitigates compliance and legal risks by ensuring AI systems adhere to regulations and do not generate disallowed content. It also protects customer trust and brand reputation – continuous monitoring and filtering of outputs reduces the chance of offensive or errant content reaching the public. In practice, guardrails can include content moderation filters, toxicity classifiers, fact-checking modules, or rules that enforce the model to follow certain guidelines. While guardrails won’t catch every issue, they significantly reduce AI risks and, when combined with human oversight and testing, help maintain safe, fair, and compliant AI deployments. By putting guardrails in place, organizations can confidently deploy GenAI to drive innovation without “veering off course” into outcomes that might harm users or violate standards.
Cluster Management Across Environments
GenAI models are computationally intensive and often require specialized hardware (GPUs, TPUs). Cluster management refers to efficiently orchestrating a cluster of computing resources (servers, GPU, CPU nodes, etc.) to run AI workloads across on-premises data centers, cloud, or hybrid environments. Effective cluster management is important because it provides fast provisioning, scalability, and high availability for AI services. For example, Bud AI Foundry’s cluster management enables end-to-end management of heterogeneous AI clusters – whether at the edge, in the data center, or across multi-cloud setups. This kind of tooling automates the deployment and administration of compute clusters and coordinates resources like GPUs, networking, and storage. Bud’s AI Foundry also have advanced cluster management capabilities, allowing organizations to efficiently orchestrate and scale their GenAI workloads. By optimizing resource allocation, monitoring performance in real time, and enabling seamless scaling across environments, Bud ensures that enterprises can run AI applications with reliability, efficiency, and cost-effectiveness.
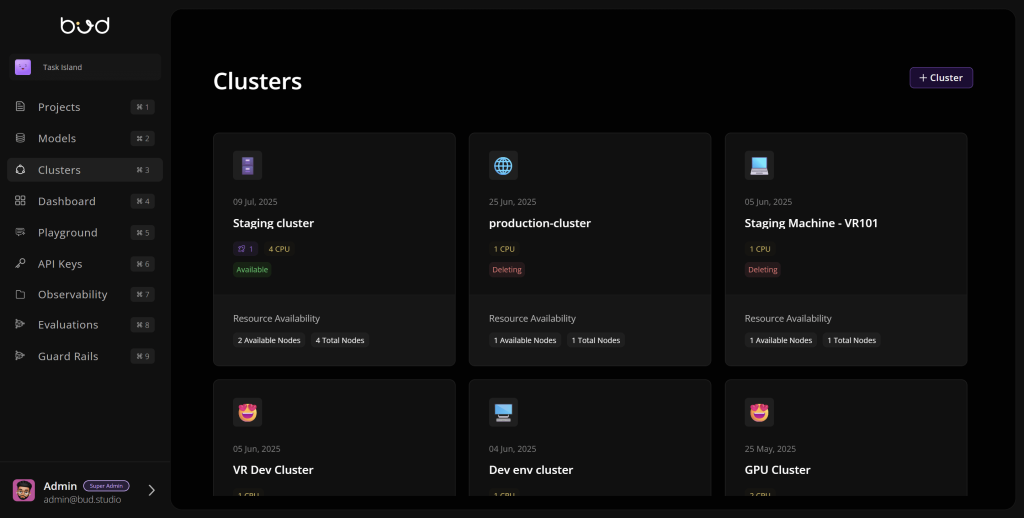
Why does this matter for GenAI in production?
First, many enterprises adopt a hybrid cloud strategy for AI: certain sensitive workloads run on-premises (for data control or lower latency), while others leverage the public cloud for elasticity. A unified cluster management approach allows teams to run the GenAI models where it makes most sense (on-prem for data locality or low latency, cloud for burst capacity) without a fragmented experience. It ensures consistent environment configuration, container orchestration (often via Kubernetes), and job scheduling across these venues.
Second, robust cluster management supports reliability and scaling – it can monitor node health, rebalance workloads if a server fails, and add more nodes during peak usage. This prevents downtime and allows the GenAI service to meet SLAs. Finally, cluster managers can optimize resource utilization and cost, for instance by scheduling jobs to fully utilize GPU capabilities or by shutting down idle instances. In essence, strong cluster management provides the backbone for scalable, efficient, and portable GenAI deployments, enabling teams to focus on models and applications rather than low-level infrastructure wrangling.
Model Management and Versioning
Building a GenAI application is not a one-and-done effort – models evolve over time. Model management is the practice of tracking and governing the lifecycle of AI models, from development through production. This includes versioning models, evaluating their performance, and controlling which versions are deployed. Good model management is necessary to ensure reliable outputs and a controlled deployment process. AI models are not static assets; they require monitoring, periodic retraining or fine-tuning, and eventual retirement or replacement as data or business needs change. Without a structured approach to manage these changes, organizations can face fragmented efforts and “operational chaos” when deploying GenAI at scale.
Leading enterprises treat model management as a first-class discipline. For example, eBay built an internal platform as a central gateway for all AI models, supporting both proprietary and open-source models, with unified APIs for inference and fine-tuning. This platform approach allows their data science teams to consistently handle essential functions: dataset preparation, model training, deployment/inferencing, and continuous evaluation. Consolidating these functions yields consistency and efficiency in the ML pipeline. Moreover, a Model Registry is a critical tool within model management. It acts as a repository where models are cataloged with metadata, version numbers, and evaluation metrics. Using a registry, teams can compare different model versions on quality metrics and maintain an “approval” status for deployment. Only models that pass tests and review are marked as approved, and pipelines can automatically deploy the approved version to production. This prevents untested changes from reaching users. In short, robust model management ensures traceability (knowing which model is running), reproducibility (knowing how it was built), and governance (ensuring it meets quality and compliance standards). It reduces the risk of deploying a faulty model and makes it easier to roll back to a prior version if needed. As GenAI innovation accelerates, having centralized model management is increasingly important to handle the pace of model updates without sacrificing control.
Experiments and Evaluations
Before deploying (and while operating) generative AI models, teams must conduct rigorous experiments and evaluations. This involves testing different model candidates, fine-tuning parameters, and assessing output quality using defined metrics or human feedback. The importance of this step is twofold: choosing the best model for the task, and continuously improving it. Generative models can behave in unexpected ways, so robust evaluation is needed to ensure the model meets business requirements (accuracy, tone, safety, etc.) before it goes live. The image below shows the model playground feature in Bud AI foundry. Using it, you can easily test models and compare different models simultaneously.
In practice, an experimentation phase might include A/B testing multiple model architectures or prompt strategies, running the models on validation datasets, and measuring results (for example, measuring an LLM’s accuracy on factual Q&A or a content quality score). It’s crucial to evaluate not just overall performance, but also check for biases or failure modes during this phase. Systematic evaluation allows teams to iterate and only promote a model to production once it proves its worth. Even after deployment, evaluation should continue. As Amazon notes, observability and evaluation are critical aspects for maintaining and improving generative AI applications. Evaluation means assessing the quality and relevance of the AI’s outputs and collecting feedback to refine the model. This could be done via automated metrics or by leveraging human-in-the-loop reviews. Bud AI foundry currently supports 300+ evals out of the box, making your experiments much more easier and faster.
By instituting continuous evaluation, organizations can catch issues like model drift or quality regressions early. For example, one best practice is to use automated tests or “LLM judges” to score model outputs on each new version, ensuring that any code change or retraining yields an improvement (or at least no degradation) in quality. This kind of systematic check (instead of ad-hoc manual tests) makes the improvement process reliable and repeatable. Overall, a culture of experimentation and evaluation helps maintain high performance and relevance of GenAI models over time. It provides the evidence base (quantitative metrics, user studies, etc.) to confidently deploy a model and to demonstrate that the model is getting better with each iteration.
Deployment Observability and Monitoring
Once a generative AI model is live, having deployment observability is essential to keep it running optimally. Observability means the ability to monitor, measure, and understand the internal state of the AI system by analyzing its metrics and logs. In a traditional software context, observability might include uptime monitoring, error logging, and performance metrics – and all of these apply to GenAI deployments as well. Additionally, AI observability encompasses tracking the model’s predictions and behavior: how long are inference calls taking, how often is the model returning incomplete answers, what kinds of prompts are causing errors, etc.
There are several reasons why observability is crucial for GenAI in production. Performance monitoring is one: continuous tracking of key metrics (latency, throughput, GPU/memory utilization, and even output accuracy if measurable) helps ensure the model meets its service level objectives. If latency spikes or error rates increase, the ops team can get alerted and troubleshoot quickly. Indeed, real-time monitoring and detailed logs enable rapid detection of anomalies and their root causes – for example, spotting that a certain prompt consistently leads to the model crashing or that a new deployment caused memory usage to double.
The image above show’s Bud’s Observability dashboard. It improves the reliability and robustness of AI systems. By analyzing how the model behaves under different conditions or data inputs, teams can identify issues like model drift (where the model’s performance degrades because live data diverges from training data). Having metrics and traces over time allows data scientists to see if the model’s outputs are becoming less accurate or more biased as new data comes in, prompting retraining if needed. Moreover, many industries have regulatory or business requirements for traceability and explainability. Observability tools that capture input–output pairs, decisions made by the model, and even model internals (where possible) support compliance by creating an audit trail. For instance, if a question arises later about why the AI made a certain recommendation, robust logging can provide the necessary context.
Observability in GenAI deployments provides transparency and control over a complex “black box” system. It empowers teams to proactively optimize performance and quickly respond to any issues or unexpected behavior. This is especially important given that generative models can fail in novel ways – without monitoring, you might not even know something has gone wrong until a user reports it. A comprehensive monitoring stack for GenAI should include metrics dashboards, log analytics, and alerting systems (often leveraging existing APM/monitoring tools adapted for AI). By maintaining strong observability, organizations ensure their GenAI services remain reliable, efficient, and accountable over time.
Access Management and Security Controls
In an enterprise setting, not everyone should have unfettered access to a generative AI model or its underlying resources. Effective access management is a critical part of successfully moving a Generative AI pilot to production. It involves controlling who (or what systems) can use the GenAI model, in what way, and ensuring proper authentication, authorization, and usage oversight. This is important for multiple reasons. First, generative AI models might have access to sensitive data (during fine-tuning or via retrieval-augmented generation with private databases). You must restrict access to such models and data to authorized personnel to prevent data leaks or misuse. Second, the computational resources backing the model (e.g., GPU servers or API endpoints) are expensive and limited; uncontrolled access could lead to abuse, unintended high costs, or system overload. Third, from a security perspective, AI systems can become targets for malicious actors—for example, an attacker might try to exploit the model with adversarial prompts or extract confidential info from its training data. Strong access controls form a frontline defense.
Additionally, access management ties into API management and rate limiting for GenAI-as-a-service. If you expose a generative model via an API (say, to internal applications or external customers), you need to manage API keys, enforce rate limits or quotas, and possibly tiered access (e.g. certain users can only use the model in a read-only fashion vs. developers who can fine-tune it). These controls prevent abuse and ensure fair usage. Finally, on the security front, standard best practices apply: use encryption (HTTPS/TLS) for any data in transit to and from the model, and encrypt sensitive data at rest. Regular security reviews and tests (including checking the model for vulnerabilities like prompt injection attacks) should be part of the deployment routine. By managing access and security diligently, organizations protect both their intellectual property (the model and data) and their users, while maintaining compliance with data protection regulations.
Deployment Analytics and Performance Insights
Beyond real-time monitoring, organizations benefit from deployment analytics – the collection and analysis of data about how the generative AI is being used in production. Deployment analytics turns raw logs and usage data into insights that can inform business and technical decisions. For example, analytics can reveal which features or prompts are most popular, what times of day see the highest load, or which user segments use the AI most. It can also track the quality of interactions (e.g. user ratings of responses, or the percentage of conversations that resolve an issue successfully). These insights are important for continuous improvement and business ROI evaluation.
From a technical standpoint, analyzing usage patterns might highlight opportunities to optimize. If analytics show that 90% of queries to a chatbot are about a few limited topics, developers might decide to train a smaller specialized model for those, to improve response quality or speed. Or if certain prompts consistently lead to slow responses, engineers can investigate why (perhaps the model is doing an expensive computation or timing out on external calls). Deployment analytics also feed into capacity planning – knowing the growth rate of usage and peak concurrency helps decide when to scale infrastructure or fine-tune the model for efficiency.
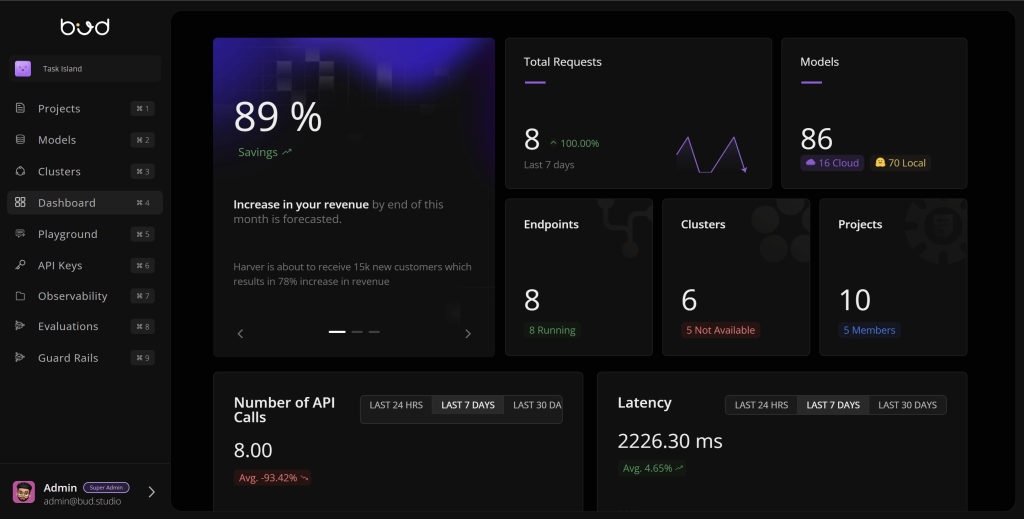
On the business side, reporting on deployment metrics is key for stakeholders. Business leaders will want to see how the GenAI deployment is contributing value: for instance, reduction in average handling time in customer support due to an AI assistant, or increased content output by a marketing team using a generative tool. These can be quantified (e.g. “the AI system handled 5,000 inquiries this week with an average satisfaction score of X, saving an estimated Y hours of manual work”). Such analytics should be regularly compiled into reports or dashboards. They demonstrate progress, justify the investment, and highlight any issues that need attention. Moreover, analyzing user feedback and behavior can uncover new use cases or required improvements. If analytics show many users asking the AI something it cannot do, that may indicate a demand for new features or knowledge expansion in the model.
In summary, deployment analytics turns the operation of GenAI into a data-driven feedback loop, which is essential for a successful Generative AI pilot to production. It complements observability (which focuses on system health) by focusing on user behavior and business KPIs. Together, they ensure the GenAI deployment is not a black box but a well-understood component of business operations. Companies that leverage these insights can iterate faster and align their GenAI services more closely with user needs and business goals.
Compliance Management and Governance
With generative AI becoming part of critical business workflows, compliance management is a non-negotiable aspect of production deployment. Compliance management means ensuring that the AI system and its outputs adhere to all relevant laws, regulations, and ethical standards – as well as the company’s own policies. This spans a broad range of considerations: data privacy, industry-specific regulations (like healthcare HIPAA or finance’s Fair Lending laws), intellectual property rights, and emerging AI governance rules (such as the EU AI Act). Failing to manage these can result in legal penalties, reputational damage, or harm to users.
One key part of compliance is data governance. Generative models often train on or utilize data that could be sensitive (personal data, proprietary information, etc.). Compliance management involves setting up processes to handle such data responsibly – for example, anonymizing or aggregating personal data, obtaining necessary user consents, and ensuring you don’t violate data residency requirements. Organizations should implement strong privacy controls and cybersecurity measures, like encrypting data and monitoring for breaches. Another aspect is algorithmic accountability: models should be audited for bias and fairness, especially if they affect decisions about individuals. Bias in AI output can lead to discriminatory outcomes, which not only violates ethical norms but can breach regulations (for instance, hiring or lending decisions assisted by AI are increasingly regulated for fairness). Compliance management means regularly testing the model for biases or inappropriate content and mitigating these issues (e.g. through retraining on more diverse data or applying guardrails as discussed earlier).
The regulatory landscape for AI is evolving fast. Governments are introducing AI-specific laws focusing on transparency, risk assessment, and human oversight. For example, the EU’s AI Act (expected by 2026) will impose strict requirements on “high-risk” AI systems, and non-compliance could incur fines up to 7% of global revenue. This underscores why companies must be proactive: building a governance framework for AI now is far better than scrambling after a law is in effect. A robust AI governance framework typically includes clear policies on acceptable AI use, an oversight committee or process (perhaps a Responsible AI board) to review new AI deployments, and documentation practices to maintain transparency. Only a small fraction of organizations today have an enterprise-wide AI governance council, but this number is likely to grow as the need for structured oversight becomes evident.
In practice, compliance management for GenAI involves cross-functional collaboration – IT, legal, risk, and business units need to work together. Before a generative AI tool is deployed, there should be a risk assessment covering security, privacy, and ethical risks. Controls should then be put in place to address those risks (for instance, content filters for certain regulated outputs, or user disclaimers where the AI might produce uncertain information). Ongoing monitoring (as described in observability) also feeds into compliance by catching when something goes out of bounds. Ultimately, emphasizing compliance and governance doesn’t slow down AI innovation – rather, it enables sustainable and scalable AI adoption by building trust. When risk and compliance teams establish clear guardrails and review processes, they turn themselves from “blockers” into enablers who help the business deploy GenAI quickly but safely. This trusted foundation is crucial for scaling AI initiatives in any heavily regulated industry or public-facing application.
Portability and Flexibility (Models and Hardware)
The AI field is advancing rapidly, and organizations may need to switch between different models or hardware platforms to achieve the best results. Easy portability in GenAI deployments refers to the ability to migrate models across environments (on-premises to cloud, or between cloud providers) and to run on various hardware with minimal friction. This is important to avoid vendor lock-in and to future-proof your AI infrastructure. For instance, a company might start with a certain GPU type or cloud service, but later find a better option (like a more cost-effective cloud, or specialized AI accelerators). If the deployment is portable, the team can redeploy the model in the new environment without a complete overhaul.
One way to ensure portability is to use containerization and open standards. Packaging models and inference code into Docker containers, orchestrated by Kubernetes, has become common – it abstracts away the underlying server specifics so that the same container can run on different hardware or clouds. Another aspect is using framework-agnostic model formats like Bud Runtime which keeps your AI infrastructure vendor-neutral, allowing deployment anywhere from local servers to any cloud. This kind of approach makes it easier to switch model providers or move between in-house and hosted models as needed. For example, an organization might prototype using OpenAI’s GPT via API, but later decide to deploy a fine-tuned open-source model internally for cost or data privacy reasons. With good portability practices, the transition can be smoother.
Portability also applies to swapping out the model itself, which is a crucial consideration when moving a Generative AI pilot to production. Perhaps a new model with better performance emerges—the infrastructure should allow updating to that model without extensive rework. Techniques like decoupling the model interface (using an internal API or abstraction layer) can help. If the application code doesn’t hardcode too many assumptions about a specific model, you can plug in a new model that follows the same interface. Moreover, portability between hardware means the deployment can leverage advancements like new GPU generations or AI chips (TPUs, IPUs, etc.) for better performance or cost-efficiency. Container orchestration can schedule workloads to the appropriate hardware if multiple types are available.
In summary, emphasizing portability gives an organization flexibility. It ensures that your GenAI deployment can adapt to changing needs, whether that’s migrating to a more compliant environment, scaling to different regions, or adopting the latest AI innovations. It reduces the risk of being stuck with a suboptimal vendor or technology. In a space as dynamic as AI, this flexibility is a significant strategic advantage.
ROI Analytics and Reporting
Generative AI projects can be resource-intensive – both in terms of computing costs and the effort to develop and maintain them. Business leaders will understandably look for the return on investment (ROI). It’s critical to have ROI analytics and reporting mechanisms to quantify the value generated by the GenAI deployment and to inform decision-makers about its impact. Measuring AI’s ROI can be challenging, especially early on, but it’s not impossible. The key is identifying the right metrics that tie AI usage to business outcomes.
One immediate area where GenAI often shows value is efficiency gains. Many generative AI deployments aim to automate or speed up tasks – for example, drafting marketing content, coding assistance, handling level-1 customer queries, etc. These efficiencies might not directly show up as revenue, but they save time for employees or improve throughput. Traditional ROI looks at financial gain vs. investment, but with GenAI the initial value “overwhelmingly comes from improved efficiency” rather than direct new revenue. For instance, if an AI writing assistant allows marketing staff to produce content twice as fast, the “gain” is the freed-up time and possibly better content quality. ROI reports should capture such metrics: e.g. content volume per person pre- and post-AI, or reduction in support ticket handling time by the AI chatbot. Over time, these efficiency gains can translate to cost savings (needing fewer outsourcing resources, etc.) and enable growth (more projects handled by the same team).
Another aspect is quality and outcome improvements. Generative AI might improve the quality of outputs (like more personalized customer responses, or better analytical reports). These can lead to indirect ROI such as higher customer satisfaction, increased sales conversion, or faster R&D cycles. For example, a pharmaceutical company might use GenAI to hypothesize new drug molecules faster; while hard to measure in immediate dollars, it has value in potentially bringing medicines to market sooner. ROI analysis should encompass these dimensions, even if they require proxy measures (customer satisfaction scores, product development timeline improvements, etc.).
It’s also important to track the costs side by side. GenAI incurs cloud compute costs, maybe new hires or training costs for prompt engineers or AI specialists, and ongoing maintenance. A comprehensive ROI report will include these investments and compare them to the benefits achieved. In the early stages of moving a Generative AI pilot to production, it’s possible ROI will appear neutral or even negative because of upfront costs – stakeholders need to be informed of this expected trajectory. Over the longer term, ROI should turn positive through productivity gains and new capabilities, but this must be demonstrated with data. Reporting might take the form of dashboards for operational metrics plus periodic business reviews that cover qualitative benefits and strategic value. For instance, a quarterly report might show that the GenAI system handled X thousand queries with an estimated saving of Y labor hours, and highlight a couple of success stories or improvements made.
Lastly, ROI analytics help in identifying further opportunities. By seeing which areas the GenAI provides the most value, leadership can decide where to extend or invest more. Conversely, if some aspect isn’t yielding enough benefit, it might need rethinking. In essence, ROI reporting closes the loop by ensuring the GenAI deployment remains aligned with business objectives and continues to justify its existence with tangible (or at least quantifiable) results. It keeps the focus on value creation rather than deploying AI for AI’s sake.
Other Considerations for Production GenAI
In addition to the major items above, a few other considerations are worth noting for a truly production-ready generative AI deployment:
- High Availability and Resilience: Production systems should be designed with failover and redundancy. For GenAI, this could mean having multiple instances of the model running in different zones or a way to quickly load a model on new hardware if one fails. This ensures that even if a server crashes, the service remains available with minimal disruption.
- Continuous Integration/Continuous Deployment (CI/CD): Treat your GenAI model and application like any other software product. Automate the testing of new models (on offline evaluation sets) and integrate deployment into CI/CD pipelines. This allows rapid iteration while maintaining quality. For instance, every time a data scientist registers a new model version, a CI pipeline could run integration tests (ensuring the application works with the new model) before automatic deployment.
- Testing and Validation: Go beyond just evaluating raw model accuracy. In production, you should test the entire GenAI application. This includes unit tests for prompt templates or chain-of-thought logic if using an agent, and integration tests where the AI is inserted into a realistic scenario (e.g. simulating a user query). Also, validate that the model output not only is correct, but also conforms to any required format or business rules (for example, not including prohibited content – effectively testing the guardrails).
- Explainability (where needed): In some use cases, especially in regulated industries, explaining why the AI produced a certain output can be important. While deep neural networks are black boxes, techniques like logging the source of information (in retrieval-augmented generation, logging which documents were retrieved) or using simpler surrogate models for explanation can be helpful. This ties into observability and compliance, ensuring decisions made by AI can be interpreted when necessary.
- User Feedback Loops: Provide mechanisms for end-users or internal users to give feedback on the AI’s outputs (e.g., a “Was this answer helpful?” prompt). This data is extremely valuable for guiding further improvements. It can be used in re-training the model or adjusting prompts, and also serves as a form of continual evaluation.
- Cost Management: Generative AI, especially large models, can be expensive to run at scale. Monitoring and optimizing cost is a practical part of deployment. This might involve scheduling heavy jobs (like re-training or batch generations) for off-peak hours, using lower-cost hardware when feasible, or even employing smaller distilled models for certain tasks to save compute. Keeping an eye on the cost per inference and overall compute spend ensures the deployment remains financially sustainable and informs the ROI calculations.
Each of these considerations contributes to a robust deployment. Overlooking them could mean the difference between a Generative AI pilot to production project that works in the lab and a reliable service that thrives in production.
In summary,
Transitioning a Generative AI pilot to production is a multidisciplinary challenge. It requires not just a fine-tuned model, but a fine-tuned plan addressing technology, people, and processes. By considering the technical aspects alongside strategic aspects, enterprises can avoid the fate of stagnating pilots and instead achieve scalable AI success. The best practices and checklist provided in this report serve as a comprehensive framework to evaluate and guide GenAI deployments.
In essence, moving a Generative AI pilot to production is about institutionalizing the innovation – embedding the AI into the fabric of the business in a reliable, responsible way. With proper preparation and oversight, organizations can harness GenAI’s transformative potential while managing risks, ultimately turning promising prototypes into impactful, enduring solutions that drive business value.







.png)


