
Unlock 55X savings on the Total Cost of Ownership for your GenAI solutions!













Bud Runtime is a Generative AI serving and inference optimization software stack that delivers state-of-the-art performance across any hardware and OS. It ensures production-ready deployments on CPUs, HPUs, NPUs, and GPUs.
Supports On-prem, Cloud & Edge Deployments
Built-in Cluster Management
Built-in LLM Gaurdrails and model monitoring
Advanced LLM Observability
Active Prompt Analysis, Prompt Optimisations
Supports Model Editing, Model Merging
White House & EU AI Guidelines compliant
Secure: Compliant with CWE and MITRE ATT&CK
GenAI ROI Analysis, Reporting & Analtics
Enterprise support, User management
Throughput Increase
60-200%
Speed Increase
12X

A single, unified set of APIs for building portable GenAI applications that can scale across various hardware architectures, platforms, clouds, clients, edge, and web environments, ensuring consistent and reliable performance in all deployments.
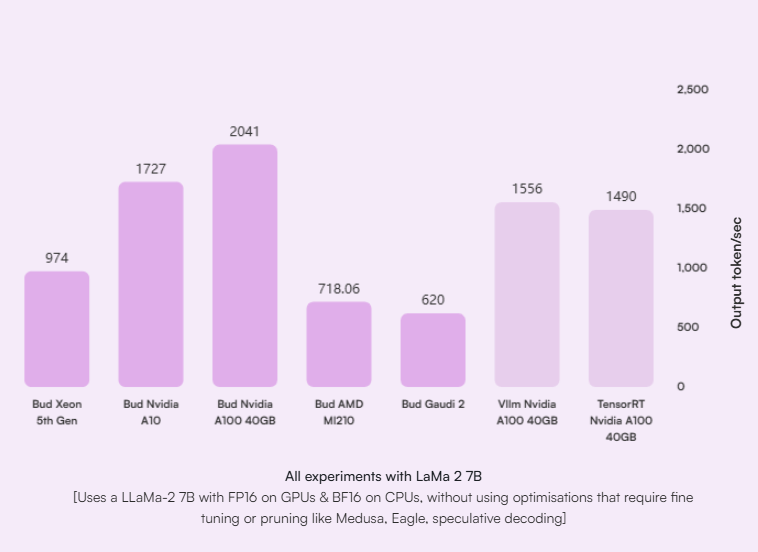
For the first time, Bud Runtime has made CPU inference throughput, latency, and scalability comparable to NVIDIA GPUs. Additionally, Bud Runtime delivers state-of-the-art performance across various hardware types, including HPUs, AMD ROCm, and AMD/Arm CPUs.
Current GPU systems often underutilize CPUs and RAM after model loading. Bud Runtime takes advantage of this unused infrastructure to boost throughput by 60-70%. It enables the scaling of GenAI applications across various hardware and operating systems within the same cluster, allowing for seamless operation on NVIDIA, Intel, and AMD devices simultaneously.






















Our estimates shows that CPU usage for Inference could reduce the power consumption of LLMs by 48.9% while providing production ready throughput and latency.
Read PublicationIntuitive Dashboard
Insightful Analytics and Reports
Seamless model management
Post production management
Metrics, prompts, cache, compression management
Hit ratio, robustness management
LLaMa Index
LangChain
Guidance
Haystack
Shareable and easy to use interface for model testing & comparison
Analyse decoding methods using a UI
Programming language for LLMs
Chat history & function calling
LLaMa Index
LangChain
Guidance
Haystack
One click deployment & production.
Hardware agnostic deployment
Operating System agnostic
Hybrid Inference
LLaMa Index
LangChain
Guidance
Haystack
Streamline GenAI development with Bud’s serving stack that enables building portable, scalable and reliable applications across diverse platforms and architectures, all through a singular API for peak performance.
GenAI Made Practical, Profitable and Scalable!
.png)



© 2025, Bud Ecosystem Inc. All right reserved.