
As LLMs continue to grow, boasting billions to trillions of parameters, they offer unprecedented capabilities in natural language understanding and generation. However, their immense size also introduces major challenges related to memory usage, processing power, and energy consumption. To tackle these issues, researchers have turned to strategies like the Sparse Mixture-of-Experts (SMoE) architecture, which has emerged as a promising solution for more efficient model deployment.
The research paper, Efficient Expert Pruning for Sparse Mixture-of-Experts Language Models, introduces a new method to optimise inference in large language models (LLMs). Building on the Sparse Mixture-of-Experts (SMoE) architecture, which itself offers promising advantages, the paper addresses the limitations of SMoE related to large parameter counts and substantial GPU memory requirements. The authors present Efficient Expert Pruning (EEP), a novel approach that enhances inference efficiency and demonstrates notable improvements in performance. For instance, EEP achieves a remarkable increase in accuracy on the SQuAD dataset, rising from 53.4% to 75.4%, showcasing its effectiveness in enhancing model performance.
What is Sparse Mixture-of-Experts?
Research has shown that only a subset of a model’s parameters are essential for its performance on specific tasks. To streamline model inference, unnecessary parts of a neural network can be removed through a technique called pruning.
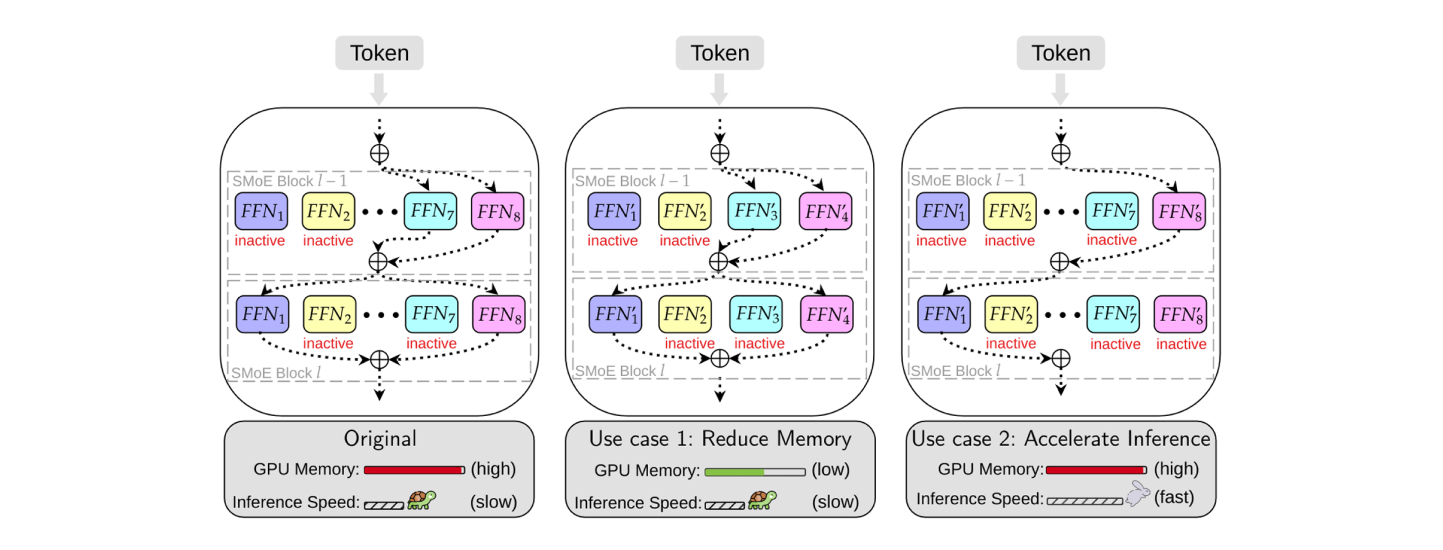
Sparse Mixture-of-Experts (SMoE) is a specialised architecture used in LLMs to boost efficiency during inference. Unlike traditional LLMs that use all their parameters for every task, SMoE activates only a small, targeted subset of parameters for each individual task or piece of data (referred to as a “token”). This selective activation not only speeds up processing but also maintains high performance, making the model more efficient overall.
By engaging only a portion of the model’s parameters at a time, SMoE models greatly reduce the demands on memory and processing power. For instance, although the Mixtral 8 × 7B model contains 47 billion parameters, it activates only 13 billion parameters to handle certain tasks and outperforms or matches the Llama-2 70 billion model and GPT-3.5 on many benchmarks. This targeted activation makes the model faster and more resource-efficient, enabling it to perform complex tasks without the extensive computational costs typically associated with such large models.
Even though SMoE models use less processing power for each individual task, they still have a lot of parameters, which means they require a lot of memory. This can make them challenging to use in various situations because they need a lot of memory to work properly.
Additionally, these models might not handle large batches of tasks efficiently because the amount of memory on a device limits how many tasks can be processed at once. So, it’s important to find new ways to make SMoE models smaller and more manageable without losing their effectiveness.
One effective approach is expert pruning for SMoE models, which is a form of structured pruning. This method targets specific parts of the model to improve overall efficiency. Recent advances in expert pruning have achieved up to 25%-50% reduction in parameters and faster processing times. However, this approach can sometimes lead to a drop in performance or require additional fine-tuning, which demands a lot of GPU memory and resources. Therefore, it is crucial to develop more efficient pruning methods that can effectively reduce the size of SMoE models while staying within the limits of available resources.
Efficient Expert Pruning
To tackle the aforementioned challenges, the authors developed a new technique called Efficient Expert Pruning (EEP). EEP is a gradient-free evolutionary strategy designed to optimise the pruning process for SMoE models. EEP involves two main steps: expert pruning and expert merging.
- Expert Pruning: This step removes less important parts of the model, or "experts," to reduce the model&aposs size and memory usage. They do this by searching for and keeping only the most important experts without changing the model’s other parameters.
- Expert Merging: After pruning, the team consolidates the knowledge from the removed experts into the remaining ones. This helps the model retain its performance even after reducing its size.
The team found that reducing the number of experts can actually improve performance. For example, in their tests, reducing the number of experts from 8 to 2 led to a significant performance boost on some tasks.
- Improved Efficiency: By reducing the number of active experts (those used for processing data), the model becomes more efficient. They observed that fewer active experts can speed up processing times, making the model faster.
- Better Generalisation: The new method works well across various types of data and tasks, including those that the model hasn’t seen before. It consistently performs better than other methods in their tests.
- Gradient-Free Approach: Unlike traditional methods that require lots of computation and memory to fine-tune the model, EEP doesn’t need these complex calculations. This makes it more practical and affordable to use.
The EEP method introduces an innovative approach for transferring knowledge from an old model to a pruned one by merging weights. This new technique effectively reduces the size of large language models while maintaining their performance. It stands out for its efficiency, requiring less computational power and resources, and is versatile enough to be applied across a wide range of tasks.

Evolutionary Strategies For Enhancing performance of SMoE architectures
Evolutionary Strategies are a type of optimization technique inspired by the natural process of evolution. It doesn’t rely on gradient information (which measures how to adjust parameters based on changes) but instead evolves solutions over time through processes similar to biological evolution.
In Evolutionary Strategies, the process begins by generating a diverse set of possible solutions to the problem at hand. Each of these solutions is then evaluated to determine how well it performs. The best-performing solutions are selected to create new ones. This is done by mixing features from the top solutions, akin to combining traits in offspring, and introducing small random changes, or mutations, to explore new possibilities. This cycle of generating, evaluating, combining, and mutating solutions is repeated over several rounds, or generations, allowing the solutions to gradually improve and evolve.
The research team used Evolutionary Strategy because it is well-suited for handling the complex and large search space of the router mapping and expert merging matrices in SMoE models, without the need for expensive gradient computations. This approach allows for effective optimization and adaptation, making it practical and efficient for their specific problem.
Key Results and Observations
The key results and observations from the experiments are;
- The application of EEP while maintaining only 4 experts resulted in improved performance and cost-effectiveness for most tasks compared to using all available experts.
- When the model was constrained to just 2 experts, EEP frequently matched or exceeded the performance of the full model across five tasks.
- EEP is more effective than other methods for deciding which experts to keep. It maintains high accuracy and avoids problems that occur when too many experts are removed.
- After pruning experts, combining or merging the remaining experts results in substantial performance boosts. For example, improvements of 5%-7% were seen in certain tasks (like WIC, CB, and SQuAD), helping to retain important knowledge from the removed experts.
- EEP works well not just on smaller models but also on larger ones, including advanced versions of models like Mixtral and Qwen. This suggests that EEP is a versatile and effective method for optimising models of different sizes.
Efficient Expert Pruning (EEP) represents a major advancement in the field of AI model optimization. By addressing the dual challenges of memory usage and inference speed, EEP makes Sparse Mixture-of-Experts models more practical for deployment in real-world scenarios. The ability to prune experts effectively and achieve better or equivalent performance on downstream tasks marks a significant step forward in AI research and application.







.png)


