

Together with NxtGen Cloud, we’re excited to introduce M for Coding — a coding assistant launched under NxtGen Cloud’s M GenAI platform and powered by Bud’s code-generation models and infrastructure. This is India’s alternative to Claude Code, delivering the same powerful coding experience at a much more cost-effective rate.
India’s Alternative to Claude Code
India is home to one of the world’s largest developer communities, boasting over six million developers across the country. A significant portion of this talent pool is concentrated in startups, small and medium-sized enterprises (SMEs), and academic institutions. These groups often operate under tight budget constraints, making cost one of the primary barriers to accessing advanced development tools. Despite their potential and innovation capabilities, many are unable to afford the high licensing fees charged by global AI coding tools such as Copilot or Claude. This cost sensitivity creates a divide—those who can afford cutting-edge tools gain a significant productivity edge, while the rest are left behind.
This disparity becomes even more concerning in the context of India’s broader national goals. Initiatives like Digital India and Atmanirbhar Bharat (self-reliant India) emphasize the need for homegrown solutions that can empower local developers and reduce dependency on expensive foreign technologies. An affordable, indigenous coding assistant would not only align with these national missions but also accelerate them by putting powerful AI capabilities into the hands of every developer, regardless of their budget.
Moreover, democratizing access to AI development tools is essential for fostering grassroots innovation. When students, hobbyists, and early-stage startups can experiment without financial barriers, they are more likely to innovate, iterate, and build solutions that address real-world problems. Affordability, in this context, isn’t just about saving money—it’s about unlocking creative potential at scale.
On a larger scale, enterprises and government bodies, which often manage large teams of developers, also stand to benefit significantly from cost-effective AI coding solutions. Reducing the per-user cost of AI tools can result in substantial savings, especially when deployed across hundreds or thousands of seats. More importantly, it can lead to faster development cycles, improved code quality, and accelerated digital transformation efforts within both public and private sectors.
In essence, the need for an affordable coding tool in India goes beyond economics—it is a strategic necessity. It represents an opportunity to empower millions, foster self-reliance, and fuel the next wave of digital innovation from the grassroots to the enterprise level.
Performance
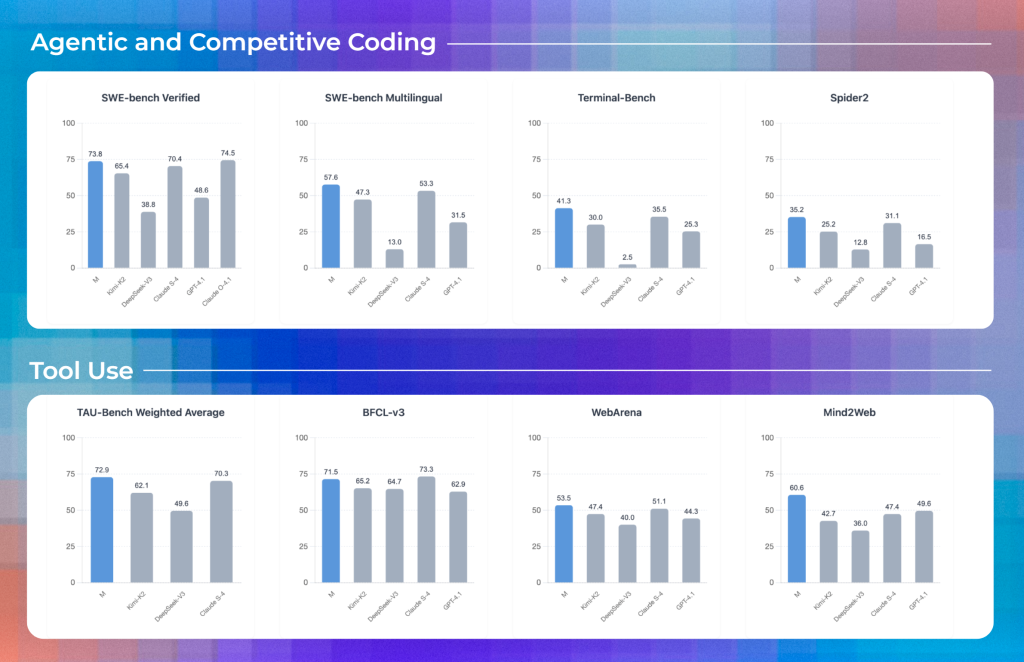
The benchmark provided below highlights M’s performance across three main categories: Agentic Coding, Agentic Browser Use, and Agentic Tool Use. Broadly, M consistently performs at or above parity with leading frontier models, excelling in multi-turn coding tasks, browser-based reasoning, and tool orchestration.
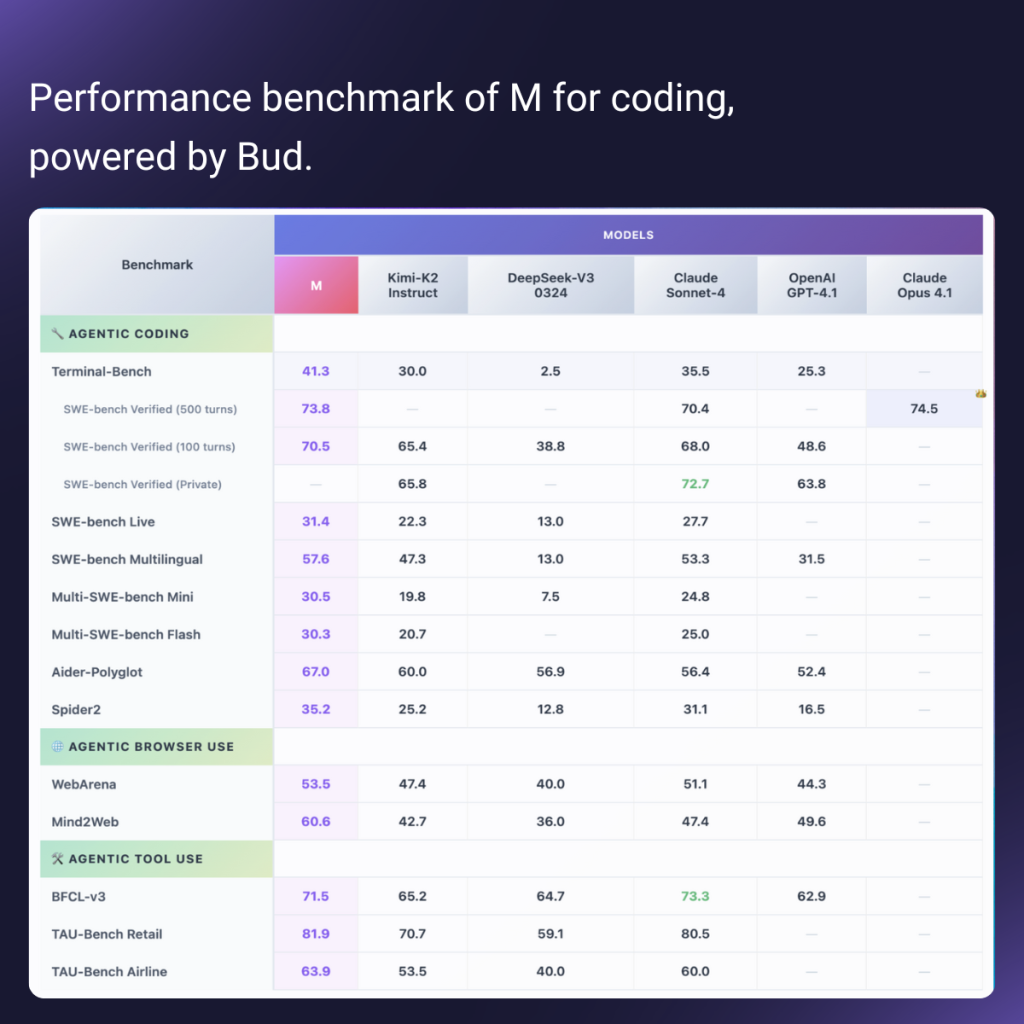
Agentic Coding
M demonstrates strong coding abilities, especially in long-horizon reasoning tasks. M is optimized for sustained, multi-turn coding workflows, with performance clustered at the top end of benchmarks.
- SWE-bench Verified (500 turns): 73.8, ahead of Claude Sonnet-4 (70.4) and close to Claude Opus 4.1 (74.5). This positions M among the very top performers for multi-turn software engineering problems.
- SWE-bench Verified (100 turns): 70.5, outperforming OpenAI GPT-4.1 (48.6) and close to Claude Sonnet-4 (68.0).
- Aider-Polyglot: 67.0, ahead of most peers except Claude Sonnet-4 (56.4) and comparable to Opus.
- Weaknesses: On live or flash coding challenges (SWE-bench Live, Flash), M dips slightly, though still competitive.
Agentic Browser Use
M’s WebArena (53.5) and Mind2Web (60.6) scores are strong, consistently higher than OpenAI GPT-4.1 and Claude Sonnet-4. This shows robust reasoning in real-world, web-based tasks, which is critical for automation, research agents, and workflow assistance.
Agentic Tool Use
M shines in tool coordination benchmarks, M has best-in-class tool orchestration, making it suitable for enterprise-scale automation and agentic workflows where multiple APIs/tools need to be integrated.
- BFCL-v3: 71.5, ahead of GPT-4.1 (62.9) and competitive with Claude Sonnet-4 (73.3).
- TAU-Bench Retail: 81.9, surpassing all peers, with a margin over Claude Sonnet-4 (80.5).
- TAU-Bench Airline: 83.5, outperforming Claude Sonnet-4 (74.8).
Comparative Insights
M establishes itself as a frontier-grade coding and agentic model, excelling in multi-turn software engineering, web reasoning, and tool orchestration. Its standout strength is in long-horizon coding benchmarks (SWE-bench 500) and real-world tool use (TAU-Bench, BFCL), where it leads or ties with the very best.
This positions M as a generalist agent model with particular dominance in enterprise-grade automation workflows, giving it a strong edge for practical coding agents, browser-integrated assistants, and autonomous tool-driven systems.
- Against Claude Sonnet-4 & Opus 4.1: M is often on par or slightly stronger, particularly in tool use and long-horizon coding. Opus edges ahead slightly in certain SWE-bench subsets, but M is consistently competitive.
- Against GPT-4.1: M clearly outperforms GPT-4.1 across almost all benchmarks, especially in coding and tool integration.
- Against DeepSeek & Kimi-K2: M shows a substantial lead, particularly in complex reasoning and agentic tasks, suggesting it belongs in the frontier model tier.







.png)


